Мы уже немало писали про технологию использования хранилищ VVols (например, здесь и здесь), которая позволяет существенно увеличить производительность операций по работе с хранилищами в среде VMware vSphere за счет использования отдельных логических томов под компоненты виртуальных машин и передачи части операций по работе с ними на сторону дисковых массивов.
Давайте посмотрим, как же технология VVols влияет на процесс резервного копирования виртуальных машин, например, с помощью основного продукта для бэкапа ВМ Veeam Backup and Replication, который полностью поддерживает VVols. Для начала рассмотрим основные способы резервного копирования, которые есть в виртуальной среде:
Резервное копирование за счет монтирования виртуальных дисков (Hot Add backup) - в этом случае к одной ВМ монтируется диск VMDK другой ВМ и происходит его резервное копирование
Резервное копирование по сети передачи данных (NBD backup) - это обычное резервное копирование ВМ по сети Ethernet, когда снимается снапшот ВМ (команды отдаются хостом ESXi), основной диск передается на бэкап таргет, а потом снапшот применяется к основному диску ("склеивается" с ним) и машина продолжает работать как раньше.
Резервное копирование по сети SAN (SAN-to-SAN backup) - в этом случае на выделенном сервере (Backup Server) через специальный механизм Virtual Disk API происходит снятие снапшота ВМ без задействования хоста ESXi и бэкап машины на целевое хранилище напрямую в сети SAN без задействования среды Ethernet.
Последний способ - самый быстрый и эффективный, но он требует наличия специальных интерфейсов (vSphere APIs и Virtual Disk Development Kit, VDDK), которые должны присутствовать на выделенном сервере.
К сожалению, для VVols способ резервного копирования по сети SAN еще не поддерживается, так как данный механизм для прямой работы с хранилищами SAN для VVols еще не разработан. Поэтому при работе с VVols придется использовать NBD backup. Однако не расстраивайтесь - большинство компаний именно его и используют для резервного копирования машин на томах VMFS в силу различных причин.
Работа хоста VMware ESXi с томами виртуальной машины VVols выглядит следующим образом:
Для процессинга операций используется Protocol Endpoint (PE), который представляет собой специальный административный LUN на хранилище. PE работает с лунами машин (VVols), которые представлены через secondary LUN ID, а VASA Provider со стороны дискового массива снабжает vCenter информацией о саблунах виртуальных машин, чтобы хост ESXi мог с ними работать через PE.
Таким образом, в новой архитектуре VVols пока не прикрутили технологический процесс соединения стороннего сервера с VVols виртуальных машин и снятия с них резервных копий.
Вернемся к процессу резервного копирования. Как известно, он опирается на механизм работы снапшотов (Snapshots) - перед снятием резервной копии у ВМ делается снапшот, который позволяет перевести базовый диск в Read Only, а изменения писать в дельта-диск снапшота. Далее базовый диск ВМ копируется бэкап-сервером, ну а после того, как базовый диск скопирован, снапшот склеивается с основным диском, возвращая диски машины обратно в консолидированное состояние.
Так это работает для файловой системы VMFS, которая развертывается поверх LUN дискового массива. Сами понимаете, что при интенсивной нагрузке во время резервного копирования (особенно больших виртуальных дисков) с момента снятия снапшота может пройти довольно много времени. Поэтому в дельта-дисках может накопиться много данных, и процесс консолидации снапшота на практике иногда занимает часы!
Для виртуальных томов VVols все работает несколько иначе. Давайте взглянем на видео:
В среде VVols при снятии снапшота базовый диск остается режиме Read/Write (это все делает массив), то есть контекст записи данных никуда не переключается, и изменения пишутся в базовый диск. В снапшоты (это отдельные тома VVol) пишется только информация об изменениях базового диска (какие дисковые блоки были изменены с момента снятия снапшота).
Ну а при удалении снапшота по окончанию резервного копирования никакой консолидации с базовым диском производить не требуется - так как мы продолжаем с ним работать, просто отбрасывая дельта-диски.
Такой рабочий процесс несколько увеличивает время создания снапшота в среде VVols:
Но это всего лишь десятки секунд разницы. А вот время консолидации снапшота по окончанию резервного копирования уменьшается во много раз:
Как следствие, мы имеем уменьшение совокупного времени резервного копирования до 30%:
Так что, если говорить с точки зрения резервного копирования виртуальных машин, переход на VVols обязательно даст вам прирост производительности операций резервного копирования и позволит уменьшить ваше окно РК.
Недавно мы писали том, что компания Код Безопасности, производитель решений номер 1 для защиты виртуальных сред, выпустила обновление продукта vGate R2 версии 2.8. Эта версия прошла инспекционный контроль в ФСТЭК России и доступна для загрузки и покупки. В обновленную версию vGate R2 добавлены новые механизмы защиты и расширенные функции по администрированию системы. Сегодня мы расскажем о том, как в vGate R2 выглядит рабочий процесс для пользователей в защищенной среде.
Недавно Cormac Hogan написал интересный пост о том, как нужно настраивать "растянутый" между двумя площадками HA-кластер на платформе VMware vSphere, которая использует отказоустойчивую архитектуру Virtual SAN.
Напомним, как это должно выглядеть (два сайта на разнесенных площадках и witness-хост, который обрабатывает ситуации разделения площадок):
Основная идея такой конфигурации в том, что при отказе отдельного хоста или его компонентов виртуальная машина обязательно должна запуститься на той же площадке, где и была до этого, а в случае отказа всей площадки (аварии) - машины должны быть автоматически запущены на резервном сайте.
Откроем настройки кластера HA. Во-первых, он должен быть включен (Turn on vSphere HA), и средства обнаружения сетевых отказов кластера (Host Monitoring) также должны быть включены:
Host Monitoring позволяет хостам кластера обмениваться сигналами доступности (heartbeats) и в случае отказа предпринимать определенные действия с виртуальными машинами отказавшего хоста.
Для того, чтобы виртуальная машина всегда находилась на своей площадке в случае отказа хоста (и использовала локальные копии данных на виртуальных дисках VMDK), нужно создать Affinity Rules, которые определяют правила перезапуска ВМ на определенных группах хостов в рамках соответствующей площадки. При этом эти правила должны быть "Soft" (так называемые should rules), то есть они будут соблюдаться при возможности, но при отказе всей площадки они будут нарушены, чтобы запустить машины на резервном сайте.
Далее переходим к настройке "Host Hardware Monitoring - VM Component Protection":
На данный момент кластер VSAN не поддерживает VMCP (VM Component Protection), поэтому данную настройку надо оставить выключенной. Напомним, что VMCP - это новая функция VMware vSphere 6.0, которая позволяет восстанавливать виртуальные машины на хранилищах, которые попали в состояние All Paths Down (APD) или Permanent Device Loss (PDL). Соответственно, все что касается APD и PDL будет выставлено в Disabled:
Теперь посмотрим на картинку выше - следующей опцией идет Virtual Machine Monitoring - механизм, перезапускающий виртуальную машину в случае отсутствия сигналов от VMware Tools. Ее можно использовать или нет по вашему усмотрению - оба варианта полностью поддерживаются.
На этой же кариинке мы видим настройки Host Isolation и Responce for Host Isolation - это действие, которое будет предпринято в случае, если хост обнаруживает себя изолированным от основной сети управления. Тут VMware однозначно рекомендует выставить действие "Power off and restart VMs", чтобы в случае отделения хоста от основной сети он самостоятельно погасил виртуальные машины, а мастер-хост кластера HA дал команду на ее восстановление на одном из полноценных хостов.
Далее идут настройки Admission Control:
Здесь VMware настоятельно рекомендует использовать Admission Control по простой причине - для растянутых кластеров характерно требование самого высокого уровня доступности (для этого он, как правило, и создается), поэтому логично гарантировать ресурсы для запуска виртуальных машин в случае отказа всей площадки. То есть правильно было бы зарезервировать 50% ресурсов по памяти и процессору. Но можно и не гарантировать прям все 100% ресурсов в случае сбоя, поэтому можно здесь поставить 30-50%, в зависимости от требований и условий работы ваших рабочих нагрузок в виртуальных машинах.
Далее идет настройка Datastore for Heartbeating:
Тут все просто - кластер Virtual SAN не поддерживает использование Datastore for Heartbeating, но такого варианта тут нет :) Поэтому надо выставить вариант "Use datastores only from the secified list" и ничего из списка не выбирать (убедиться, что ничего не выбрано). В этом случае вы получите сообщение "number of vSphere HA heartbeat datastore for this host is 0, which is less than required:2".
Убрать его можно по инструкции в KB 2004739, установив расширенную настройку кластера das.ignoreInsufficientHbDatastore = true.
Далее нужно обязательно установить кое-какие Advanced Options. Так как кластер у нас растянутый, то для обнаружения наступления события изоляции нужно использовать как минимум 2 адреса - по одному на каждой площадке, поэтому расширенная настройка das.usedefaultisolationaddress должна быть установлена в значение false. Ну и нужно добавить IP-адреса хостов, которые будут пинговаться на наступление изоляции хост-серверов VMware ESXi - это настройки das.isolationaddress0 и das.isolationaddress1.
Таким образом мы получаем следующие рекомендуемые настройки растянутого кластера HA совместно с кластером Virtual SAN:
vSphere HA
Turn on
Host Monitoring
Enabled
Host Hardware Monitoring – VM Component Protection: “Protect against Storage Connectivity Loss”
Disabled (по умолчанию)
Virtual Machine Monitoring
Опционально, по умолчанию "Disabled"
Admission Control
30-50% для CPU и Memory.
Host Isolation Response
Power off and restart VMs
Datastore Heartbeats
Выбрать "Use datastores only from the specified list", но не выбирать ни одного хранилища из списка
Ну и должны быть добавлены следующие Advanced Settings:
15 октября в 15:00ИТ-ГРАД проводит презентацию новых высокопроизводительных флеш-массивов AFF от NetApp. На мероприятии вы узнаете о новой расширенной линейке флеш-массивов СХД, разработанной для корпоративных клиентов. Спикерами мероприятия выступят инженеры NetApp и ИТ-ГРАД.
Компания VMware на днях сделала доступными видеозаписи основных докладов с прошедшей недавно конференции VMware VMworld 2015, где было сделано множество интересных анонсов.
Известный блоггер Vladan Seget написал интересную статью (и даже не одну, а несколько) о различных способах развертывания средства StarWind Virtual SAN, предназначенного для создания отказоустойчивого кластера хранилищ под виртуальные машины.
Вот 3 основных метода развертывания StarWind Virtual SAN:
Обычная установка на Windows-систему. Сделать это можно в пробном режиме бесплатно, или имея соответствующую лицензию на продукт.
Более подробно об этом методе развертывания StarWind Virtual SAN написано вот тут.
Установка на бесплатный Microsoft Hyper-V Server. Этот метод не требует вообще никаких вложений, даже в лицензию на Windows Server, так как Hyper-V Server бесплатен. Но вам потребуется Windows-машина (не обязательно сервер) для установки консоли StarWind, так как в Hyper-V Server нет оконного интерфейса.
Об этом методе установки StarWind Virtual SAN написано здесь.
Установка из виртуального модуля OVF. Этот способ и описан в последней статье Владана. Такой способ установки позволяет загрузить уже готовую виртуальную машину StarWind Virtual SAN для Microsoft Hyper-V (ее можно преобразовать в формат VMware VMDK из VHDX с помощью бесплатного StarWind V2V Converter).
Все делается достаточно просто, и весь процесс занимает не более часа. Попробуйте!
На прошедшей конференции VMworld 2015 было сделано много интересных анонсов о продуктах и технологиях VMware. Мы уже писали о новой версии VMware Horizon 6.2 (которая, кстати, уже доступна для скачивания), новых возможностях VMware SRM 6.1 и новых функциях VMware Virtual SAN 6.1. В этой же статье мы расскажем о тех нововведениях, которые нас ожидают в ближайшее время в плане облачной инфраструктуры VMware vCloud Air.
Во-первых, VMware представила технологическое превью Project SkyScraper, представляющего собой набор утилит, интерфейсов и функций облачной инфраструктуры vCloud Air для создания унифицированного гибридного облака, объединяющего корпоративную инфраструктуру предприятия и облачную инфраструктуру сервис-провайдера в единое пространство вычислительных ресурсов:
В рамках процесса "гибридизации" облаков будут поддерживаться следующие возможности, функционально доступные из VMware vSphere Web Client:
Cross-Cloud vMotion - это возможность прозрачной для виртуальных машин и пользователей миграции между корпоративной инфраструктурой и облачным датацентром (и обратно) без простоя ВМ. То есть, все как при обычном vMotion. Данную возможность мы уже рассматривали в рамках описания возможностей VMware SRM 6.1. Со стороны сервис-провайдеров также будут внесены изменения в решение vCloud.
Content Sync - возможность синхронизации вспомогательной инфраструктуры для виртуальных машин и данных между частной и облачной инфраструктурой в целях обеспечения возможностей непрерывной отказо- и катастрофоустойчивости на уровне всей инфраструктуры. К синхронизируемым объектам относятся шаблоны виртуальных машин (Templates), виртуальные сервисы (vApp), ISO-файлы и скрипты, которые синхронизируются с их копиями в content catalog на стороне vCloud Air.
Эти две возможности будут доступны посредством VMware vCloud Air Hybrid Cloud Manager, загружаемого как дополнение к vSphere Web Client, и имеющего опциональные функции по управлению платными подписками на IaaS-услуги VMware.
Помимо Project SkyScraper были анонсированы следующие сервисы облака vCloud Air:
VMware vCloud Air Disaster Recovery - это возможность использовать решение SRM как услугу для создания катастрофоустойчивой инфраструктуры между своим датацентром и облаком vCloud Air.
Кстати, вот доступные цены на сервисы DRaaS от VMware (подробнее - тут):
VMware vCloud Air Object Storage - возможность облачного хранения неструктурированных файлов на уровне предприятия. Основано на платформе Google Cloud Platform:
Технический обзор этой возможности:
VMware vCloud Air SQL - это сервисы баз данных как услуги (DBaaS), которые позволяют получать ресурсы СУБД по требованию и масштабировать их по мере возрастания нагрузки. Подробнее об этом рассказано вот тут. Поддерживается Microsoft SQL.
VMware vCloud Air Hybrid Cloud Manager - консоль управления гибридной облачной инфраструктурой, совместимая с vSphere Web Client и имеющая функции управления облачными сервисами и платными услугами облака VMware vCloud.
VMware vCloud Air Advanced Networking Services - это сетевые службы, обеспечивающие перечисленные выше возможности на уровне сетевой инфраструктуры (см. картинку выше). Многие из них доступны только совместно с решением VMware NSX. К таким решениям относятся:
Intelligent Routing - средства умной маршрутизации для собственной и облачной инфраструктуры.
Strong Encryption - сервисы шифрования данных.
WAN Acceleration - сервисы сжатия и оптимизации трафика.
VXLAN extension - инструменты создания прозрачной Layer-2 инфраструктуры между собственными и облачными виртуальными машинами.
Direct connect - выделенный доступ к облачной инфраструктуре по защищенным каналам. Про эту возможность мы писали вот тут.
Сервисы гибридного облака VMware vCloud Air представлены также на вот этой инфографике. Основная страница облачных услуг VMware находится вот тут. На некоторые сервисы уже можно направить запрос на Early Access.
Многие из вас в курсе, что решение StarWind Virtual SAN обеспечивает лучшую в отрасли защиту виртуальных машин на платформе Microsoft Hyper-V за счет создания стабильно работающего отказоустойчивого кластера хранилищ.
Для тех, кто еще не развертывал этот продукт, компания StarWind подготовила видеоруководство "StarWind Virtual SAN Free: Virtualized Shared Storage for Microsoft Hyper-V. Step-by-step", в рамках которого вы сможете посмотреть, как меньше чем за час развернуть отказоустойчивый кластер хранилищ для виртуальных машин Microsoft Hyper-V (для просмотра видео потребуется заполнить форму):
Ну а для тех, кто видео смотреть не любит, есть простой и понятный документ "StarWind Virtual SAN Free Getting Started", где вся процедура описывается просто и наглядно на нескольких страницах.
Как вы знаете, на конференции VMware VMworld 2015 было сделано немало интересных анонсов. О некоторых из них мы уже писали - это объявления о выходе VMware Virtual SAN 6.1 и VMware Horizon 6.2. Сегодня мы расскажем еще об одной интересной новости с VMworld - выпуске решения для обеспечения катастрофоустойчивости виртуального датацентра VMware Site Recovery Manager 6.1.
1. Управление защитой данных на базе политик
Напомним, что в VMware vSphere есть понятие Storage Profile - это профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Виртуальную машину при создании или миграции можно разместить на хранилище, соответствующем требованиям к производительности и надежности:
В SRM 6.1 появился новый тип Protection-групп - storage policy-based protection groups. Они используют механизм vSphere Storage Profiles для идентификации виртуальных машин и добавления их в группы. Также существенно упрощается настройка защищаемых хранилищ.
Теперь профилю хранилищ, а также отдельным хранилищам, можно назначить тэг, которым можно оперировать при создании групп, сортировке или поиске элементов:
Кроме того, появилась интеграция со средствами развертывания виртуальных машин, такими как VMware vRealize Automation.
2. Поддержка растянутых кластеров и vMotion между датацентрами.
Раньше пользователям приходилось выбирать между использованием Site Recovery Manager и vSphere Metro Storage Clusters (так называемые Stretched Clusters, vMSC). Теперь обе этих технологии используются совместно.
Site Recovery Manager 6.1 теперь поддерживает и координирует исполнение операций cross-vCenter vMotion для обеспечения единого пространства отказо- и катастрофоустойчивости для распределенных датацентров:
Таким образом, SRM 6.1 вобрал в себя все преимущества "растянутых" кластеров:
Интеграция растянутых кластеров и VMware SRM 6.1 позволяет реализовать следующие сценарии, ранее доступны только в vMSC:
Плановое обслуживание оборудования целого датацентра - исполнение плана миграции виртуальных машин на другую площадку под управлением другого vCenter прозрачно для пользователей и приложений.
Нулевой простой при сбоях - исполнение плана аварийного восстановления в сочетании с cross-site vMotion (эвакуация машин) поможет избежать простоев при авариях и прочих неприятностях. Ранее такой план мог быть выполнен только путем остановки машин в основном ЦОД и последующим запуском на резервной площадке.
Вот как исполнение плана с подобным сценарием выглядит в консоли SRM:
Также функции растянутого кластера и vMotion между датацентрами будут востребованы при тестировании плана аварийного восстановления в распределенных ЦОД.
3. Улучшенная интеграция с VMware NSX.
Интеграция с решением для виртуализации сетей VMware NSX решает такие проблемы, как разделение сетей в двух датацентрах, необходимость обечить единое пространство миграции vMotion и создание изолированного сетевого окружения для тестирования плана аварийного восстановления.
Используя новые логические коммутаторы NSX, которые охватывают несколько серверов vCenter, Site Recovery Manager позволяет автоматически создать маппинги виртуальных сетевых ресурсов сред при создании плана восстановления, что снижает эксплуатационные расходы и сокращает время, необходимое для настройки.
Объекты Universal Logical Switches объединяют два сетевых домена vCenter на уровне Layer-2, позволяя создавать виртуальные группы портов, которые подключены к виртуальным коммутаторам обеих площадок.
В этом случае Site Recovery Manager автоматически определяет и сопоставляет сети основного и резервного сайтов, никаких ручных операций по настройке маппинга не требуется:
В случае сбоя на основной площадке, необходимые параметры сети и настройки безопасности (включая IP-адреса, security groups, параметры сетевого экрана и конфигурации оконечных устройств) применяются на восстанавливаемых виртуальных машинах, что дополнительно сокращает время восстановления.
Сам NSX 6.2 поддерживает автоматическую синхронизацию сетевых настроек между площадками, поэтому тестирование планов аварийного восстановления может происходить почти в автоматическом режиме, без необходимости ручных операций по приведению сетевых настроек в соответствие друг другу.
Доступность для загрузки VMware Site Recovery Manager 6.1 ожидается в ближайшее время, пока можно следить за новостями на странице обновленного продукта.
На проходящей сейчас конференции VMworld 2015 было сделано множество интересных анонсов (впрочем, как и всегда). Конечно же, мы расскажем о всех тех, что достойны внимания. Одна из самых интересных новостей - это анонс новой версии решения для создания кластеров хранилищ VMware Virtual SAN 6.1.
Давайте взглянем на новые возможности этого решения:
1. Virtual SAN Stretched Cluster.
Теперь VSAN будет позволять создавать географически "растянутый" кластер хранилищ между датацентрами, продолжая обеспечивать функции отказоустойчивости. Репликация данных при этом работает с синхронном режиме.
2. Virtual SAN for Remote Office / Branch Office (ROBO)
В VSAN теперь появилась возможность развертывать множество двухузловых кластеров хранилищ, которыми можно централизованно управлять из одной консоли отдельного VMware vCenter Server, предназначенного для этой задачи. Этот сценарий подходит для компаний с большим числом небольших филиалов:
3. Virtual SAN Replication with vSphere Replication
Virtual SAN 6.1 теперь может использовать технологию vSphere Replication для асинхронной репликации данных на любые расстояния в комбинации с VMware Site Recovery Manager (SRM), чтобы получилось полностью законченное решения для восстановления инфраструктуры после сбоев.
Например, можно создать синхронно реплицируемый растянутый кластер хранилищ на расстояниях с latency менее 5 мс, а средствами vSphere Replication откидывать данные в географически удаленный датацентр:
4. Поддержка Multi-Processor Fault Tolerance (SMP-FT).
Теперь виртуальные машины, защищенные технологией FT, полностью поддерживаются со стороны VMware Virtual SAN 6.1, то есть кластер непрерывной доступности из виртуальных машин теперь защищен как со стороны вычислительных ресурсов, так и со стороны хранилищ.
5. Поддержка Windows Server Failover Clustering (WSFC) and Oracle Real Application Cluster (RAC).
В новой версии VSAN теперь поддерживаются технологии кластеризации от Oracle и Microsoft. Для Oracle RAC можно запускать несколько экземпляров Oracle RDBMS на одном хранилище. Точно так же можно использовать и кластеры Microsoft WSFC поверх хранилищ Virtual SAN:
6. Максимальная производительность и высокая скорость отклика.
Здесь было сделано 2 серьезных улучшения:
Поддержка ULLtraDIMM SSD хранилищ, которые втыкаются в канал оперативной памяти (слоты DIMM), работающие с очень быстрым откликом на запись (менее 5 микросекунд). Это позволяет сделать хост All Flash с емкостью на 12 ТБ в форм-факторе блейд-сервера с троекратно большей производительностью, чем у внешних массивов.
NVMe – интерфейс Non-Volatile Memory Express (NVMe), который был специально разработан для SSD, чтобы максимально распараллеливать операции на программном и аппаратном уровне. В тестах VMware, использующих эту технологию, было получено 3,2 миллиона IOPS на 32-узловом кластере при примерно 100 тысячах операций в секунду на одном хост-сервере ESXi.
7. Virtual SAN Health Check Plug-in.
Теперь плагин, который был ранее доступен только на VMware Labs, стал частью решения VMware Virtual SAN 6.1. Теперь вся необходимая информация о жизнедеятельности кластера хранилищ видна в VMware vSphere Web Client:
8. Virtual SAN Management Pack for vRealize Operations.
Теперь для решения vRealize Operations есть отдельный Virtual SAN Management Pack, который позволяет осуществлять мониторинг кластера хранилищ и своевременно решать возникающие проблемы:
Более подробно о решении VMware Virtual SAN 6.1 можно узнать на этой странице. О доступности решения для загрузки будет объявлено несколько позже.
В ближайшее время мы расскажем еще о нескольких интересных анонсах с VMworld 2015 - stay tuned.
На днях компания Veeam выпустила обновленную версию продукта для комплексного мониторинга и решения проблем в виртуальной среде Veeam Management Pack v8 for System Center.
Новые возможности Veeam Management Pack v8 for System Center:
App-to-metal visibility
Это основная функция решения, которая позволяет организовать отслеживание всех компонентов физической и виртуальной инфраструктуры и связей между ними. Ниже раскрывается сущность этих улучшений, в следующих версиях эти функции будут совершенствоваться.
Полная поддержка VMware vSphere 6 - теперь поддерживаются все новые возможности, такие как Virtual Volumes Datastores (VVOLs), компоненты vCenter, лицензирования и сетевого взаимодействия.
Улучшения Veeam Task Manager for Hyper-V - в новом таск-менеджере поддерживаются виртуальные машины на хранилищах SMB 3.0, а также новые метрики, такие как CPU dispatch time. Кроме того, теперь есть представления кластера Hyper-V и полная совместимость с метриками System Center Virtual Machine Manager и Operations Manager.
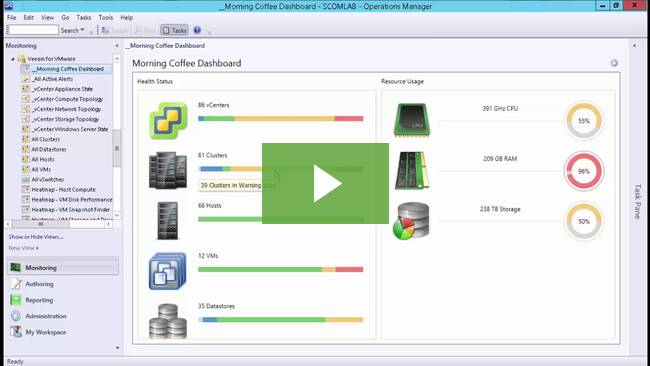
Veeam Morning Coffee Dashboard - новое представление с удобной суммарной информацией по инфраструктуре, на которое первым делом смотрит системный администратор за чашкой утреннего кофе. Отчет Morning Coffee содержит такие показатели, как "VM density" (плотность ВМ на хосте) и уровень нагрузки на вычислительные ресурсы и системы хранения.
Capacity planning and right sizing - теперь функции планирования мощностей виртуальной инфраструктуры значительно расширились и теперь содержат следующие сценарии и представления:
- Host Failure Modeling (моделирование ситуации отказа хоста)
- Performance Forecast for vSphere Datastores (прогноз производительности для хранилищ vSphere)
- Performance Forecast for Hyper-V Storage (прогноз производительности для систем хранения Hyper-V)
- Performance Forecast for vSphere and Hyper-V Clusters (прогноз производительности для кластеров vSphere и Hyper-V)
- Virtual Machine Capacity Prediction (прогноз использования ресурсов виртуальными машинами)
- Resize VMs to reclaim resources (перераспределение ресурсов виртуальных машин)
- Capacity planning for hybrid cloud (планирование ресурсов для гибридного облака)
- Capacity planning for Veeam Backup Repositories (планирование ресурсов для репозиториев Veeam Backup & Replication)
Улучшения планирования для Microsoft Azure или VMware vCloud Air
Отчет для планирования ресурсов был обновлен в соответствии с особенностями Azure и vCloud Air, и теперь с его помощью можно точно прогнозировать количество и тип ресурсов для переноса рабочих нагрузок в облако.
Улучшения отслеживания снапшотов
Забытые снапшоты и контрольные точки могут быстро разрастаться, занимать дисковое пространство и снижать производительность системы. С помощью "тепловых карт" (heat maps) вы сможете узнать, для каких виртуальных машин есть снапшоты и контрольные точки. Также доступен подробный отчет по иерархии снимков состояния, с указанием даты создания и комментариев.
Прочие улучшения:
Улучшенная визуализация топологий виртуальных ресурсов
Улучшенная видимость объектов Veeam Backup and Replication
Больше подробностей о Veeam Management Pack v8 for System Center на русском языке можно узнать на этой странице. Скачать продукт можно по этой ссылке.
Таги: Veeam, MP, Update, Microsoft, Hyper-V, System Center, SC VMM, Monitoring
Компания StarWind, известная своим продуктом StarWind Virtual SAN для создания программных отказоустойчивых хранилищ, выпустила интересный документ о своей журналируемой файловой системе - "LSFS container technical description".
Напомним, что файловая система LSFS изначально работает с большими блоками данных, что положительно сказывается на сроке службы флеш-накопителей (SSD), на которых размещаются виртуальные машины. Файловая система LSFS преобразовывает small random writes в большие последовательные операции записи, что также существенно увеличивает производительность.
Помимо этого, LSFS имеет следующие полезные функции:
встроенная поддержка снапшотов и точек восстановления хранилищ (автоматически они делаются каждые 5 минут)
поддержка непрерывной дефрагментации (она идет в фоне)
дедупликация данных "на лету" (то есть, перед записью на диск)
улучшения производительности за счет комбинирования операций записи
поддержка overprovisioning
использование технологии снапшотов и техник отслеживания изменений при синхронизации HA-узлов
Многие из вас знают о решении StarWind Virtual SAN, предназначенном для создания отказоустойчивых хранилищ. Но не все в курсе, что у StarWind есть виртуальный модуль Virtual SAN OVF (ссылка на его загрузку высылается по почте), который представляет собой шаблон виртуальной машины в формате OVF готовый к развертыванию на платформе VMware vSphere.
Недавно компания StarWind выпустила документ Virtual SAN OVF Deployment Guide, в котором описана процедура развертывания данного виртуального модуля.
Поскольку Microsoft на уровне лицензии запрещает распространение таких виртуальных модулей с гостевой ОС Windows в формате виртуальных дисков VMDK, придется сделать несколько дополнительных операций по развертыванию, а именно:
1. Запустить StarWind V2V Converter.
2. Преобразовать VHDX-диски в формат VMDK.
3. Поместить VMDK и OVF в одну папку.
4. Развернуть OVF на сервере VMware ESXi.
5. Заполнить поля IP-адреса для включения машины в виртуальную сеть.
6. Подождать окончания процесса создания и конфигурации виртуальной машины.
Больше подробностей о виртуальном модуле StarWind Virtual SAN OVF вы найдете в документе.
Таги: StarWind, Whitepaper, Virtual Appliance, OVF, Storage, HA
Не так давно компания VMware выпустила интересный документ "VMware Virtual SAN 6.0 Proof of Concept Guide", который позволяет представить себе в голове план пошаговой имплементации решения VSAN во всех его аспектах (хосты ESXi, настройка сети, тестирование решения, производительность, средства управления и т.п.).
Процесс, описанный в документе, представляет собой развертывание кластера Virtual SAN в изолированной среде для целей тестирования, чтобы обкатать решение в небольшой инфраструктуре и потом уже отправить его в производственную среду.
Основные разделы документа освещают следующие темы:
Подготовительные работы
Настройка сетевого взаимодействия
Включение функций кластера хранилищ
Функциональность платформы VMware vSphere при операциях в кластере VSAN
Симуляция аппаратных отказов и тестирование поведения кластера
Управление кластером Virtual SAN
Сам документ содержит 170 страниц и представляет собой ну очень детальное руководство по развертыванию кластера Virtual SAN и его тестированию. Причитав его, вы поймете множество интересных технических особенностей, касающихся принципов работы решения.
Скачать "VMware Virtual SAN 6.0 Proof of Concept Guide" можно по этой ссылке.
Интересный сервис по продвижению решения Virtual SAN предлагает компания VMware через своих партнеров. Поскольку сам продукт стоит очень дорого, и мало кого можно на него подписать вот так вот сразу, VMware предлагает воспользоваться услугой VSAN Assessment. Она бесплатна, может быть оказана любым партнером VMware и позволяет получить необходимую конфигурацию аппаратного обеспечения для консолидации существующих виртуальных машин в отказоустойчивых кластерах Virtual SAN (напомним, что емкость там формируется из емкости локальных дисков серверов, являющихся узлами кластеров VSAN).
Суть сервиса такова: партнер регистрирует в закрытой партнерской секции новое обследование инфраструктуры (VSAN Assessment), после чего отправляет инвайт на него потенциальному заказчику. Он, в свою очередь, скачивает готовый виртуальный модуль (Collector Appliance), настраивает его и держит запущенным в течение, по крайней мере, одной недели (минимально).
В течение этого времени происходит сбор профилей рабочей нагрузки по вводу-выводу, на основании чего можно уже нарисовать необходимые ресурсы кластера хранилищ, выбрать нужную модель сервера для узла VSAN и определить требуемое число таких узлов.
Сначала анализируется виртуальная инфраструктура VMware vSphere на площадке клиента:
Затем выводятся рекомендуемые к консолидации в кластере хранилищ виртуальные машины. Также показывается совместимость с типом кластера Virtual SAN (All-flash или гибридная модель, где данные размещаются на магнитных накопителях):
Затем мы видим требуемые ресурсы как для одного узла, так и для всего кластера Virtual SAN, а также видим, какой именно сервер и с какими аппаратными характеристиками имеется в виду (производителя сервера можно выбрать, само собой):
Ну и для того, чтобы заказчика отвлечь от высокой входной цены продукта Virtual SAN, используется метод убеждения по снижению совокупной стоимости владения (TCO - total cost of ownership) при внедрении решения VMware VSAN:
Ну и прямо расписывают вам экономию по годам:
Ну то есть, если вы все же решили потестировать технологию VMware Virtual SAN, обратитесь к своему поставщику - он заведет вам VSAN Assessment и вы сами посмотрите, какие железки рекомендуется использовать именно под ваши нагрузки по вводу-выводу для размещения виртуальных машин.
Послезавтра, 21 июля, компании Mellanox и StarWind проведут интересный вебинар "100 GbE Performance at 10 GbE Cost", посвященный построению решения для хранилищ виртуальных машин впечатляющей производительности (да-да, 100 GbE, Карл!).
Мероприятие пройдет 21 июля, в 21-00 по московскому времени:
Приходите на вебинар, чтобы узнать, как по цене 10 GbE-решения построить сеть 40 GbE на базе продуктов Mellanox (Infiniband/Ethernet) и добиться в ней 100 GbE производительности за счет решений компании StarWind (в частности, продукта Virtual SAN). Вебинар со стороны StarWind проводит Макс Коломейцев, так что вы можете задавать вопросы на русском языке.
Продолжаем знакомить наших читателей с новыми возможностями пакета решений для управления виртуальной средой и резервного копирования и репликации виртуальных машин Veeam Availability Suite v9. Напомним, что ранее мы писали про следующие его новые возможности:
В этой заметке мы расскажем про поддержку восстановления объектов СУБД Oracle в Veeam Availability Suite v9.
Veeam Explorer для Oracle предоставляет следующие возможности:
восстановление данных ВМ на уровне транзакций
восстановление на уровне отдельных таблиц
бэкап и восстановление журнала транзакций (включая накатывание транзакционного лога)
С помощью Veeam Explorer для Oracle можно восстановить базы данных Oracle на нужный момент времени с точностью до транзакции. Бэкап журнала транзакций доступен без использования агентов. Можно восстанавливать объекты БД Oracle в виртуальных машинах с гостевыми ОС как Windows, так и Linux.
Бэкапы журнала транзакций и бэкапы на уровне образа можно использовать для того, чтобы восстановить отдельные базы данных на момент, когда был создан бэкап ВМ. А можно откатить действия по журналу до определенного момента или транзакции.
Также были сделаны улучшения в других мастерах для восстановления отдельных объектов приложений из резервных копий, сделанных с помощью Veeam Backup and Replication:
Новые возможности eDiscovery в Veeam Explorer для Microsoft Exchange — подробные отчеты об экспорте с информацией о выгруженных объектах, их местоположении и критериях поиска.
В новой версии Veeam Explorer для Microsoft Active Directory появилось восстановление групповых политик, интегрированных записей DNS и конфигурационных разделов.
Veeam Explorer для Microsoft SharePoint позволяет восстанавливать отдельные веб-сайты и коллекции целиком.
В Veeam Explorer для Microsoft SQL Server доступно восстановление данных на уровне таблиц. Плюс
при работе с Veeam Explorer для Microsoft SQL Server и Veeam Explorer для Microsoft SharePoint теперь можно использовать удаленный вспомогательный сервер. Это позволит восстанавливать объекты без дополнительной нагрузки на сервер резервного копирования и обеспечит требуемый уровень производительности.
Более подробно об анонсированных новых возможностях Veeam Availability Suite v9 можно почитать в блоге компании Veeam. Выход девятой версии решения ожидается в третьем квартале 2015 года.
Мы уже писали про издание технического характера VMware Technical Journal (VMTJ), которое представляет собой периодический журнал о различного рода проблемах, которые рассматриваются научными и инженерными сотрудниками компании VMware. Некоторое время назад этот проект переехал на портал VMware Labs, посвященный различного рода разработкам, облегчающим пользователям работу с продуктами в сфере виртуализации на платформах VMware. Также там есть и ресурсы, касающиеся VMware Academic Program.
Журнал VMTJ выходит два раза в год - зимой и летом, сейчас пока доступен только зимний номер этого года (69 страниц), но к концу лета должен подоспеть и следующий.
Статьи больше похожи на научные труды - это не посты о том, как какой-нибудь VMware NSX настраивать, а более глубокие и абстрактные исследования:
FlashStream: A Multitiered Storage Architecture in Data Centers for Adaptive HTTP Streaming
Reducing Cache-Associated Context-Switch Performance Penalty Using Elastic Time Slicing
The Role of Social Graph in Content Discovery Within Enterprise Social Networking
NoETL: ETL Code Generation for a Dimensional-Data Warehouse
A Framework for Secure Offline Authentication and Key Exchange Between Mobile Devices
Just-in-Time Desktops and the Evolution of VDI
Connectivity and Collaboration in VMware vCloud Suite
Directions in Mobile Enterprise Connectivity
В конце каждой статьи идет внушительный список использованной литературы. Всего с 2012 года было выпущено 6 неморов журнала VMTJ. Вот ссылки на предыдущие выпуски:
Время от времени у пользователей VMware vSphere возникает ошибка, связанная с тем, что виртуальный диск VMDK виртуальной машины оказывается залоченным (то есть эксклюзивно используемым процессом VMX одного из хостов ESXi). В этом случае виртуальная машина не отвечает на попытки включить ее или переместить на другой хост-сервер средствами VMware vMotion. При этом процесс vmx вполне может быть запущен не на том хосте ESXi, на котором машина отображается в VMware vSphere Client или Web Client. Такое может случиться при падении хоста ESXi, массовом отключении питания или неполадках в сети SAN, а также и в некоторых других случаях.
Например, может быть вот такое сообщение об ошибке при включении машины:
Could not power on VM: Lock was not free
Для решения проблемы вам нужно найти хост ESXi, который исполняет vmx-процесс машины, и убить ВМ, которая не отвечает. После этого можно будет использовать VMDK-файл этой машины, а также включить ее, если она не работает.
Делается это следующим образом:
1. Находим хост, исполняющий vmx-процесс виртуальной машины с залоченным VMDK.
Для этого заходим по SSH на один из серверов ESXi (эта процедура работает для версий vSphere 5.5 P05 и 6.0, а также более поздних) и переходим в папку /bin:
#cd /bin
С помощью утилиты vmfsfilelockinfo ищем владельца лока нужного VMDK-файла:
Здесь vm1.vmdk - наш залоченный виртуальный диск, а 192.168.1.10 - IP-адрес сервера VMware vCenter. Вам потребуется ввести пароль его администратора.
Вывод будет примерно таким:
vmfsflelockinfo Version 1.0
Looking for lock owners on "VM1_1-000001-delta.vmdk"
"VM1_1-000001-delta.vmdk" is locked in Exclusive mode by host having mac address ['00:50:56:03:3e:f1']
Trying to make use of Fault Domain Manager
----------------------------------------------------------------------
Found 0 ESX hosts using Fault Domain Manager.
----------------------------------------------------------------------
Could not get information from Fault domain manager
Connecting to 192.168.1.10 with user administrator@vsphere.local
Password: xXxXxXxXxXx
----------------------------------------------------------------------
Found 3 ESX hosts from Virtual Center Server.
----------------------------------------------------------------------
Searching on Host 192.168.1.178
Searching on Host 192.168.1.179
Searching on Host 192.168.1.180
MAC Address : 00:50:56:03:3e:f1
Host owning the lock on the vmdk is 192.168.1.180, lockMode : Exclusive
Total time taken : 0.27 seconds.
Из вывода можно понять 2 важные вещи:
MAC-адрес хоста, залочившего VMDK
IP-адрес хоста, залочившего VMDK
Тип лока - Exclusive
Кстати, лок может быть нескольких типов:
mode 0 - нет лока
mode 1 - эксклюзивный лок (vmx-процесс машины существует и использует VMDK-диск)
mode 2 - лок только для чтения (например, для основного диска, в случае если у него есть снапшоты)
mode 3 - лок для одновременной записи с нескольких хостов (например, для кластеров MSCS или ВМ, защищенных технологией VMware Fault Tolerance).
2. Точно определяем хост, машина которого держит VMDK.
Если IP-адрес показан - хост определен. Если, мало ли, по какой-то причине его нет, можно ориентироваться на MAC-адрес. Выяснить его можно следующей командой на хосте ESXi:
# vim-cmd hostsvc/net/info | grep "mac ="
3. Обнаруживаем процесс VMX, который держит VMDK.
Выполняем на найденном ESXi команду:
# lsof | egrep 'Cartel|vm1.vmdk'
Получаем что-то вроде этого:
Cartel | World name | Type | fd | Description
36202 vmx FILE 80 /vmfs/volumes/556ce175-7f7bed3f-eb72-000c2998c47d/VM1/vm1.vmdk
Мы нашли Cartel ID нужного процесса VMX (36202). Теперь выполняем команду, чтобы найти ее World ID:
# esxcli vm process list
Получаем такой вывод:
Alternate_VM27
World ID: 36205
Process ID: 0
VMX Cartel ID: 36202
UUID: 56 4d bd a1 1d 10 98 0f-c1 41 85 ea a9 dc 9f bf
Display Name: Alternate_VM27
Config File: /vmfs/volumes/556ce175-7f7bed3f-eb72-000c2998c47d/Alternate_VM27/Alternate_VM27.vmx
Alternate_VM20
World ID: 36207
Process ID: 0
VMX Cartel ID: 36206
UUID: 56 4d bd a1 1d 10 98 0f-c1 41 85 ea a5 dc 94 5f
Display Name: Alternate_VM20
Config File: /vmfs/volumes/556ce175-7f7bed3f-eb72-000c2998c47d/Alternate_VM20/Alternate_VM20.vmx
...
Видим, что World ID нашей машины - 36205.
4. Убиваем VMX-процесс, залочивший VMDK.
Ну и убиваем зависший процесс VMX следующей командой:
# esxcli vm process kill --type force --world-id <ID>
После этого с машиной и ее диском можно делать уже что требуется.
Также для более ранних версий VMware vSphere посмотрите нашу статью вот здесь.
Совсем недавно компания StarWind Software, производитель средства номер 1 для создания отказоустойчивых программных хранилищ под виртуальные машины VMware и Microsoft - Virtual SAN, выпустила интересный документ по его бесплатному изданию - "StarWind Virtual SAN Free Getting Started".
Напомним, что полностью бесплатный продукт StarWind Virtual SAN Free позволяет превратить два новых или имеющихся у вас сервера в отказоустойчивый кластер хранения (с полностью дублированными зеркалированными узлами), который может служить для:
размещения виртуальных машин Microsoft Hyper-V (NFS/SMB3)
размещения виртуальных машин VMware vSphere (NFS)
размещения баз данных MS SQL Server (SMB3)
создания отказоустойчивого файлового сервера (SMB3/NFS)
Кстати, StarWind Virtual SAN Free - единственное решение, которое позволяет создавать HA-кластер из двух узлов неограниченной емкости абсолютно бесплатно. Более подробно об отличиях бесплатной и коммерческой версий продукта можно почитать вот в этом документе.
Таги: StarWind, Virtual SAN, Whitepaper, Storage, HA, Бесплатно, VMachines
Если вы администратор платформы виртуализации VMware vSphere, то, наверное, часто замечали, что в некоторых случаях при операциях с виртуальными машинами и ее дисками происходит "подмораживание" ВМ (или "stun", он же "quiescence"). В этот момент виртуальная машина ничего не может делать - она недоступна для взаимодействия (в консоли и по сети), а также перестает на небольшое время производить операции ввода-вывода. То есть, ее исполнение ставится на паузу на уровне инструкций, а на уровне ввода-вывода совершаются только операции, касающиеся выполняемой задачи (например, закрытие прежнего VMDK-диска и переключение операций чтения-записи на новый диск при операциях со снапшотами).
Cormac Hogan написал на эту тему интересный пост. Stun виртуальной машины нужен, как правило, для того, чтобы сделать ее на время изолированной от окружающего мира для выполнения значимых дисковых операций, например, консолидация снапшотов. Это может занимать несколько секунд (и даже десятков), но часто это происходит на время около секунды и даже меньше.
Когда может возникать stun виртуальной машины? Есть несколько таких ситуаций.
1. Во время операции "suspend" (постановка ВМ на паузу). Тут происходит такое подмораживание, чтобы скинуть память ВМ на диск, после чего перевести ее в приостановленное состояние.
2. В момент создания снапшота. Об этом написано выше - нужно закрыть старый диск и начать писать в новый. На время этой операции логично, что приостанавливается ввод-вывод.
3. Консолидация снапшотов (удаление всех). Здесь тоже нужно "склеить" все VMDK-диски (предварительно закрыв) и начать работать с основным диском ВМ. А вот удаление снапшота в цепочке stun не вызывает, так как не затрагивает VMDK, в который сейчас непосредственно идет запись.
4. Горячая миграция vMotion. Сначала память передается от одной машины к целевой ВМ без подмораживания, но затем происходит такой же stun, как и при операции suspend, с тем только отличием, что маленький остаток памяти (минимальная дельта) передается не на диск, а по сети. После этого происходит операция resume уже на целевом хосте. Пользователь этого переключения, как правило, не замечает, так как время этого переключения очень жестко контролируется и чаще всего не достигает 1 секунды. Если память гостевой ОС будет меняться очень быстро, то vMotion может затянуться именно во время этого переключения (нужно передать последнюю дельту).
5. Горячая миграция хранилищ Storage vMotion. Здесь stun случается аж дважды: сначала vSphere должна поставить Mirror Driver, который будет реплицировать в синхронном режиме операции ввода-вывода на целевое хранилище. При постановке этого драйвера происходит кратковременный stun (нужно также закрыть диски). Но и при переключении работы ВМ на второе хранилище происходит stun, так как нужно удалить mirror driver, а значит снова переоткрыть диски уже на целевом хранилище.
В современных версиях vSphere работа со снапшотами была оптимизирована, поэтому подмораживания виртуальной машины во время этих операций вы почти не заметите.
Сегодня мы посмотрим, что еще нового будет в новой версии. Вторая запись в блоге Veeam рассказывает нам о том, что Veeam Availability Suite v9 будет поддерживать прямой доступ к хранилищам NAS/NFS при резервном копировании. Раньше пользователи NFS-массивов чувствовали себя несколько "обделенными" в возможностях, так как Veeam не поддерживал режим прямой интеграции с таким типом дисковым массивов, как это было для блочных хранилищ.
Теперь же появилась штука, называемая Direct NFS, позволяющая сделать резервную копию ВМ по протоколам NFS v3 и новому NFS 4.1 (его поддержка появилась только в vSphere 6.0), не задействуя хост-сервер для копирования данных:
Специальный клиент NFS (который появился еще в 8-й версии) при включении Direct NFS получает доступ к файлам виртуальных машин на томах, для которых можно делать резервное копирование и репликацию без участия VMware ESXi, что заметно повышает скорость операций.
Кроме этого, была улучшена поддержка дисковых массивов NetApp. В версии 9 к интеграции с NetApp добавилась поддержка резервного копирования из хранилищ SnapMirror и SnapVault. Теперь можно будет создавать аппаратные снимки (с учетом состояния приложений) с минимальным воздействием на виртуальную среду, реплицировать точки восстановления на резервный дисковый массив NetApp с применением техник SnapMirror или SnapVault, а уже оттуда выполнять бэкап виртуальных машин.
При этом процесс резервного копирования не отбирает производительность у основной СХД, ведь операции ввода-вывода происходят на резервном хранилище:
Ну и еще одна полезная штука в плане поддержки аппаратных снимков хранилищ от Veeam. Теперь появится фича Sandbox On-Demand, которая позволяет создать виртуальную лабораторию, запустив виртуальные машины напрямую из снапшотов томов уровня хранилищ. Такая лаборатория может быть использована как для проверки резервных копий на восстановляемость (сразу запускаем ВМ и смотрим, все ли в ней работает, после этого выключаем лабораторию, оставляя резервные копии неизменными), так и для быстрого клонирования наборов сервисов (создали несколько ВМ, после чего создали снапшот и запустили машины из него). То есть, можно сделать как бы снимок состояния многомашинного сервиса (например, БД-сервер приложений-клиент) и запустить его в изолированном окружении для тестов, ну или много чего еще можно придумать.
Veeam Availability Suite v9 ожидается к выпуску, скорее всего, в третьем квартале 2015 года. Следить за новостями по этому решению можно вот тут.
Документ состоит из двух частей: в первой части рассказывается о том, как правильно спроектировать кластер vMSC и настроить платформу VMware vSphere соответствующим образом:
Во второй части подробно описаны различные сценарии сбоев и их обработка кластером vMSC в вашей распределенной виртуальной инфраструктуре:
В документе описаны следующие виды сбоев:
Отказ одного хоста в основном датацентре
Изоляция одного хоста в основном датацентре
Разделение пула виртуальных хранилищ
Разделение датацентра на сегменты (сети хостов и сети хранилищ)
Отказ дисковой полки в основном ЦОД
Полный отказ всех хранилищ в основном датацентре
Потеря устройств (полный выход из строя, выведение из эксплуатации) - Permanent Device Loss (PDL)
Понятное дело, что документ обязателен к прочтению, если вы планируете строить распределенную инфраструктуру для ваших виртуальных машин на платформе VMware vSphere 6.0.
В блоге компании VMware появился интересный пост с некоторыми подробностями о работе технологии репликации виртуальных машин vSphere Replication. Приведем здесь основные полезные моменты.
Во-первых, репликация с точки зрения синхронизации данных, бывает двух типов:
Full sync - это когда требуется полная синхронизация виртуальной машины и всех ее дисков в целевое местоположение. Для этого в версии VMware vSphere 5.x использовалось сравнение контрольных сумм дисков на исходном и целевом хранилище. Если они не совпадают, и нужно делать Full sync, исходя из начальных условий - начинается процесс полной репликации ВМ. В первую очередь, основным подвидом этого типа является Initial full sync - первичная синхронизация работающей виртуальной машины, для которой репликация включается впервые.
Кроме того, полная синхронизация включается, когда по какой-либо причине произошла ошибка отслеживания блоков виртуального диска машины при дельта-репликации и передать на целевую ВМ только изменения виртуальных дисков становится невозможным.
Delta sync - после того, как полная синхронизация закончена, начинается процесс передачи целевой ВМ только различий с момента полной репликации. Тут используется технология changed block tracking, чтобы понять, какие блоки надо отреплицировать с последнего Full sync. Периодичность дельта-репликации зависит от установленной политики Recovery Point Objective (RPO).
Чтобы политика RPO соблюдалась нужно, чтобы дельта-синхронизация полностью проходила за половину времени, установленного в RPO, иначе будут нарушения политики, сообщения о которых вы увидите в vSphere Client. Почему половину? Подробно мы писали об этом вот тут (почитайте, очень интересно). Также еще и в документации VMware есть информация о расписании репликации.
Если вы настроите репликацию для виртуальной машины, то автоматически работать она будет для включенной ВМ, а если она выключена, то сама работать не будет, о чем будет выдано соответствующее предупреждение:
Вот так запускается репликация для выключенной ВМ:
Во время offline-репликации виртуальную машину нельзя включить, а ее диски будут залочены. Кроме того, вы не сможете отменить эту операцию. Поэтому при нажатии Sync Now будет выведено вот такое предупреждение:
Обычно offline-репликация используется для создания гарантированной копии ВМ на другой площадке (например, при переезде датацентра или частичном восстановлении инфраструктуры на другом оборудовании). Ну или если у вас была настроена online-репликация, а вы выключили ВМ, то в конце нужно сделать еще ручной Sync Now.
Также в VMware vSphere 6.0 было сделано существенное улучшение в производительности процесса репликации. Если раньше идентичность копий основного диска и реплики сверялась только на базе контрольных сумм (все данные диска надо прочитать - а это затратно по вводу-выводу и CPU), то теперь иногда используются данные о конфигурации виртуального диска на базе регионов. Например, если на исходном диске есть регионы, которые не были аллоцированы на целевом диске, то репликация это отслеживает и передает данные в эти регионы на целевое хранилище. Это работает значительно быстрее вычисления контрольных сумм.
Но такая оптимизация работает не для всех типов виртуальных дисков, а только для Lazy zeroed thick disks, thin disks и vSAN sparse disks и только на томах VMFS. Тома NFS, тома VVols, а также диски типа Eager zeroed thick не предоставляют информации об аллокации регионов, поэтому для них оптимизация работать не будет. Более подробно об этом написано тут.
Дункан опубликовал в своем блоге интересный пост про то, как кластер VMware Virtual SAN размещает данные больших VMDK-дисков на малых физических дисках. Напомним, что Virtual SAN оперирует понятием дисковых страйпов (disk stripes), на которые разбивается дисковый объект (в частности, виртуальный диск VMDK является дисковым объектом). Это как кирпичики Virtual SAN, на уровне которых работает кластер.
Давайте взглянем на картинку:
Здесь мы видим вот что: на уровне политики (VSAN Policy) задан параметр "Number of failures to tolerate" (подробнее об этом мы писали тут) равный 1. Это значит, что инфраструктура Virtual SAN может пережить отказ не более одного хоста.
Но также в рамках политики есть еще и параметр "Stripe Width" (он же "Number of Disk Stripes Per Object"), который позволяет разбить дисковый объект на два страйпа: stripe/a и stripe/b, причем обратите внимание, что реплика дискового объекта может храниться на разных хост-серверах (а может и на одном - это вы никак не сможете отрегулировать, гарантируется лишь, что это будут 2 разных hdd-диска). Так что, если у вас маленькие диски, а виртуальные машины с большими дисками VMDK, то задайте этот параметр вот здесь:
Кстати говоря, объекты разбиваются на страйпы не только при заданном Stripe Width, но и автоматически, когда размер VMDK превышает 256 ГБ.
Как некоторые из вас знают, компания VMware в последний год активно двигает продажи не просто платформы VMware vSphere, а ее "расширенной" версии со средствами мониторинга и управления (есть даже пакеты Acceleration Kit с обязательной добавкой Operations Management). По-сути, vSphere with Operations Management - это vSphere плюс vRealize Operations Standard.
Помните про такой сайт VMware Walkthroughs, где собраны обучающие интерактивные материалы, с помощью которых можно виртуально "пощупать" продукты VMware, в частности vSphere и Virtual SAN? Так вот недавно этот ресурс пополнился материалами про vSphere with Operations Management.
Теперь всем желающим доступны материалы на следующие темы об Operations Management:
Все из вас знают замечательный продукт для организации отказоустойчивых кластеров хранилищ под виртуальные машины StarWind Virtual SAN. О его возможностях мы уже писали тут и в специальном разделе о продуктах компании.
На днях пришла отличная новость - StarWind завершила сертификацию своего ПО в рамках программы Citrix XenServer 6.5 Certification, и, таким образом, работоспособность решения Virtual SAN подтверждена официально со стороны основной тройки вендоров платформ:
Мы точно знаем, что вам всем интересно узнать, какова же реальная производительность продукта номер 1 для создания отказоустойчивых программных хранилищ StarWind Virtual SAN. Поэтому-то и приглашаем вас на бесплатный вебинар "Get Unbelievable Performance without Expensive All-Flash Arrays", где вы узнаете как достичь высокой производительности подсистемы хранения виртуальных машин, не покупая дорогостоящие All-flash хранилища.
Вебинар пройдет 16 июня в 21-00 по московскому времени. Мероприятие проводит продакт-менеджер StarWind Макс Коломейцев. Вопросы можно задавать на русском языке! Регистрируйтесь!
Интересная история произошла тут между компаниями VMware и Nutanix. Инженеры и сейлы из VMware решили провести сравнение производительности программных отказоустойчивых кластеров на базе локальных хранилищ серверов VMware Virtual SAN и Nutanix. Создав тестовую конфигурацию и выбрав профиль нагрузки, компания VMware сделала тест в средах Virtual SAN и Nutanix.
Кстати, вот конфигурация тестового кластера хранилищ:
4 x Dell XC630-10 для Nutanix,
4 x Dell R630 для vSphere с кластером VSAN
2 x Intel E5-2690 v3 на сервер
12 ядер на процессор 2.6GHz, 256 ГБ памяти на сервер
Двухпортовый 10Gb Ethernet
1 x PERC H730 Mini на сервер
2 x 400GB Intel S3700 на сервер
6 дисков x 1TB 7200 RPM NL-SAS (Seagate) на сервер
Но тут спецы из VMware решили заглянуть в EULA Nutanix, а там написано (п. 2.1, подпункт e):
You must not disclose the results of testing, benchmarking or other performance or evaluation information related to the Software or the product to any third party without the prior written consent of Nutanix
То есть, публиковать результаты тестирования нельзя. Вот такой облом. А ведь VMware много раз ругали за то, что она сама запрещает публиковать результаты тестирования производительности с конкурирующими продуктами. Это также зафиксировано в EULA:
You may use the Software to conduct internal performance testing and benchmarking studies. You may only publish or otherwise distribute the results of such studies to third parties as follows: (a) if with respect to VMware’s Workstation or Fusion products, only if You provide a copy of Your study to benchmark@vmware.com prior to distribution; (b) if with respect to any other Software, only if VMware has reviewed and approved of the methodology, assumptions and other parameters of the study (please contact VMware at benchmark@vmware.com to request such review and approval) prior to such publication and distribution.
VMware, конечно, утверждает, что у нее условия мягче, но по-сути у них написано одно и то же. Публиковать результаты тестов без разрешения нельзя. А разрешение, конечно, никто не даст, так как опубликовать конкуренты захотят только, если у них все работает лучше и быстрее.
Поэтому VMware ничего не оставалось, как опубликовать результаты только своих тестов и разбить их по профилям нагрузки, отметив, что желающие сравнить пользователи сами могут убедиться, что Nutanix работает медленнее, проведя тесты самостоятельно.
Надо также отметить, что VMware отправила запрос на публикацию в Nutanix, на что получила ожидаемый ответ - публиковать нельзя.
Ну и, собственно, результаты тестирования для кластера Virtual SAN:
Один из лидеров на рынке резервного копирования и управления виртуальной инфраструктурой, компания Veeam Software, официально объявила о запуске во втором квартале 2015 года новой версии лучшего решения для резервного копирования, репликации и управления виртуальной средой - Veeam Availability Suite v9. Напомним, что о возможностях пакета Veeam Availability Suite v8 мы писали вот тут.
Пока стало известно о двух новых возможностях продукта. А именно:
1. Интеграция с технологией EMC Storage Snapshots в Veeam Availability Suite v9.
Многие пользователи Veeam Backup and Replication задавали вопрос, когда же будет сделана интеграция с дисковыми массивами EMC. Теперь она будет добавлена для СХД линеек EMC VNX и EMC VNXe.
Интеграция с хранилищами EMC означает поддержку обеих техник - Veeam Explorer for Storage Snapshots recovery и Backup from Storage snapshots, то есть можно смотреть содержимое снапшотов уровня хранилища и восстанавливать оттуда виртуальные машины (и другие сущности - файлы или объекты приложений), а также делать бэкап из таких снапшотов.
Иллюстрация восстановления из снапшота на хранилище EMC:
Иллюстрация процесса резервного копирования (Veeam Backup Proxy читает данные напрямую со снапшота всего тома, сделанного на хранилище EMC):
Более подробно об этих возможностях можно почитать в блоге Veeam.
2. Veeam Cloud Connect - теперь с возможностью репликации.
Как вы помните, в прошлом году компания Veeam выпустила средство Veeam Cloud Connect, которое позволяет осуществлять резервное копирование в облако практически любого сервис-провайдера. Теперь к этой возможности прибавится еще и возможность репликации ВМ в облако, что невероятно удобно для быстрого восстановления работоспособности сервисов в случае большой или маленькой беды:
Кстати, Veeam Cloud Connect инкапуслирует весь передаваемый трафик в один-единственный порт, что позволяет не открывать диапазоны портов при соединении с инфраструктурой сервис-провайдера. Очень удобно.
При восстановлении в случае аварии или катастрофы основного сайта, возможно не только полное восстановление инфраструктуры, но и частичное - когда часть продуктивной нагрузки запущено на основной площадке, а другая часть (например, отказавшая стойка) - на площадке провайдера. При этом Veeam Backup обеспечивает сетевое взаимодействие между виртуальными машинами обеих площадок за счет встроенных компонентов (network extension appliances), которые обеспечивают сохранение единого пространства адресации.
Ну а сервис-провайдеры с появлением репликации от Veeam получают в свои руки полный спектр средств для организации DR-площадки в аренду для своих клиентов:
Более подробно о репликации Veeam Cloud Connect рассказано в блоге Veeam. Сам продукт ожидается к выпуску, скорее всего (как сказал Антон Гостев), в третьем квартале 2015 года. Следить за новостями по Veeam Availability Suite v9 можно вот тут.

 RSS
RSS